



|
|
|
|
|
|
|
|
The Data Mining Process | |
|
Data Mining builds models, which are abstractions of reality as shown in the data. Building and validating the models is a process. |
As illustrated in Nautilus Systems' diagram of the Data Mining Process below, the Data Mining Process involves a significant amount of time spent in data preparation, as well as model building and validation. Information learned during discovery frequently sends the analyst back to data preparation, or even to clarification of the problem statement. For a much more in-depth presentation of our data mining approach, please contact us! 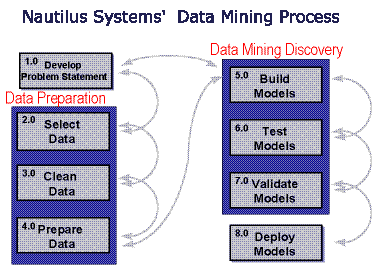 Stages 2-4. Data Preparation. 50% to 90% of the time is spent preparing the data. Data selection involves identification of internal and external data, such as adding demographic data to customer data. Data cleansing involves identification of metadata: the true definition of each data element, and resolution of inconsistencies, missing values, and data currency issues. Additional data preparation includes activities such as sampling, preprocessing, coding of discrete values, and the like. Stages 5-7. Data Mining Discovery. Data Mining Discovery may use a variety of techniques, such as traditional statistical analysis, decision trees, neural networks, and visualization techniques. In this stage, we allocate data to testing as well as training datasets, and modeling and testing is iterative. The Data Mining Purpose is to model reality, thus, if the model works, we use it. Stage 8. Deploy Models. When significant results have been found, the models are incorporated into decision support systems or OLAPs, or even into existing production systems.
|
 Data Mining differs from traditional data analysis in that it discovers patterns that were previously overlooked, as opposed to queries or statistical methods which require the analyst to make an assumption.
Data Mining differs from traditional data analysis in that it discovers patterns that were previously overlooked, as opposed to queries or statistical methods which require the analyst to make an assumption.